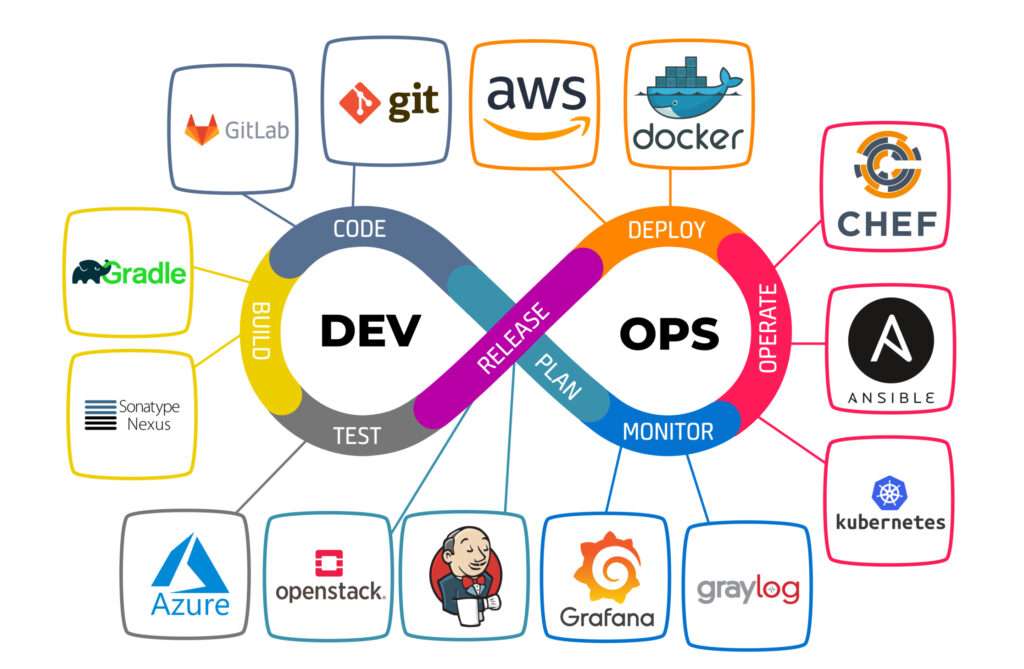
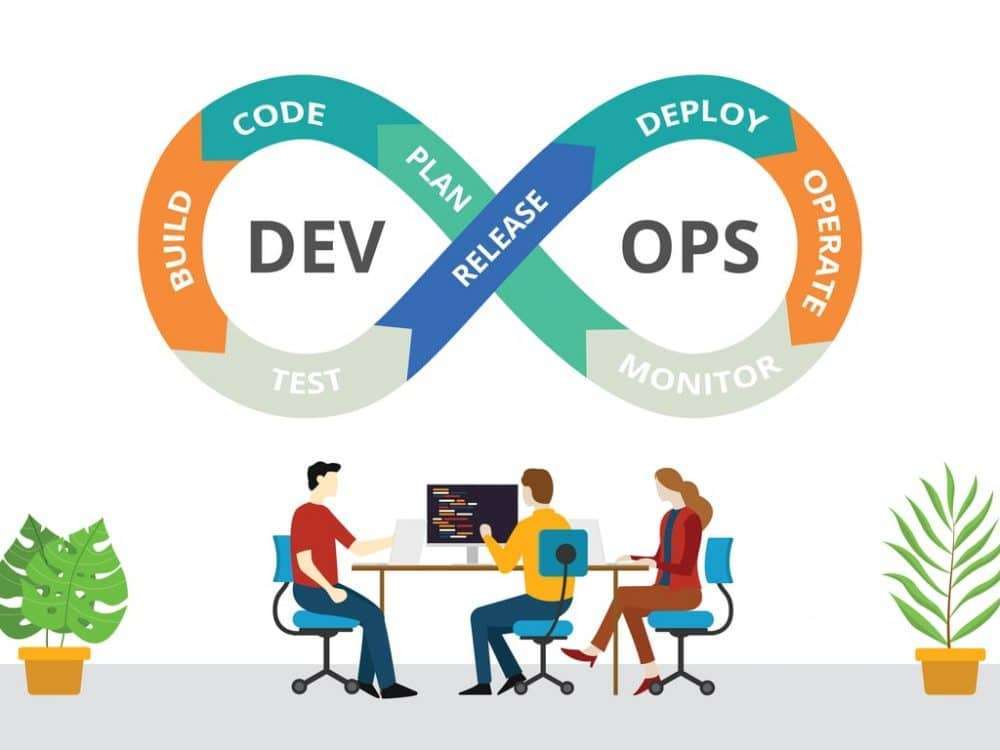
What is DevOps, and why is it important? DevOps is a set of practices that combines software development (Dev) and IT operations (Ops) to automate and streamline the software delivery process. It aims to increase collaboration, improve efficiency, and shorten development cycles. Explain the key principles of DevOps. The key principles of DevOps include collaboration, automation, continuous integration, continuous delivery/deployment (CI/CD), monitoring, and feedback. These principles emphasize communication, automation, and the rapid delivery of high-quality software. What is the role of version control systems in DevOps, and name some popular version control tools. Version control systems (VCS) track changes to source code and other files, enabling collaboration and tracking of changes over time. Popular VCS tools include Git, Subversion (SVN), and Mercurial. Explain continuous integration (CI) and continuous delivery (CD) in DevOps. Continuous Integration (CI): Developers frequently merge their code changes into a shared repository, where automated tests are run to detect integration issues early. Continuous Delivery (CD): Automated deployments to production or staging environments are possible at any time, but manual approval may be required for release. What are the key benefits of using containerization in DevOps? Containerization (e.g., Docker) provides benefits such as consistency, portability, and isolation. Containers package applications and their dependencies, making it easier to deploy and scale applications across different environments. Explain the concept of Infrastructure as Code (IaC). Infrastructure as Code is the practice of defining and provisioning infrastructure using code and automation scripts. It allows for consistent, version-controlled, and repeatable infrastructure deployments. What is the purpose of configuration management tools in DevOps, and name some examples. Configuration management tools (e.g., Ansible, Puppet, Chef) automate the management and configuration of servers and infrastructure. They ensure consistency and reduce manual configuration errors. What is continuous monitoring in DevOps, and why is it important? Continuous monitoring involves real-time tracking and analysis of application and infrastructure performance, security, and health. It helps identify issues early and ensures that systems meet performance and security requirements. What is the role of DevOps in the context of security (DevSecOps)? DevOps integrates security practices into the software development and deployment process. DevSecOps emphasizes security early in the development lifecycle, automates security testing, and encourages collaboration between security and development teams. Explain the concept of “shift-left” in DevOps. “Shift-left” refers to the practice of moving tasks such as testing, security, and quality assurance earlier in the software development lifecycle, rather than addressing them late in production. This helps catch and fix issues sooner. What is Blue-Green Deployment, and how does it work in DevOps? Blue-Green Deployment involves maintaining two identical environments: the “blue” (current) and “green” (new) environments. The switch between them is seamless, allowing for easy rollback if issues are detected in the “green” environment. What is the role of DevOps in cloud computing and serverless architectures? DevOps practices are well-suited to cloud computing and serverless architectures because they facilitate the automated provisioning, scaling, and management of resources, making it easier to develop and deploy applications in these environments. How do you handle versioning of artifacts in a CI/CD pipeline? Artifacts (e.g., software packages, binaries) should be versioned and stored in a repository (e.g., Nexus, JFrog Artifactory). Versioning ensures traceability and repeatability of deployments in the CI/CD pipeline. Explain the concept of “immutable infrastructure” in DevOps. Immutable infrastructure involves creating and deploying infrastructure components (e.g., VMs, containers) as static, unchangeable artifacts. When changes are needed, new instances are deployed instead of modifying existing ones. How do you measure the success of a DevOps implementation? Success can be measured through key performance indicators (KPIs) such as reduced lead time, increased deployment frequency, lower error rates, and improved collaboration between development and operations teams. What is DevOps, and how does it differ from traditional software development methodologies? – DevOps is a set of practices that aim to automate and integrate the processes of software development and IT operations to deliver software more quickly and reliably. Unlike traditional methods, DevOps emphasizes collaboration, automation, and continuous delivery. Explain the purpose of version control systems in DevOps. – Version control systems (VCS) like Git are essential in DevOps to manage source code, track changes, collaborate on code, and enable continuous integration. They help maintain a history of code changes and facilitate collaboration among development and operations teams. What is Continuous Integration (CI), and how does Jenkins facilitate CI? – CI is a DevOps practice where code changes are frequently integrated into a shared repository and automatically tested. Jenkins is a popular CI tool that automates building, testing, and deploying code changes. It ensures that new code is continually integrated and verified. What is Continuous Deployment (CD), and how does it differ from Continuous Delivery? – Continuous Deployment (CD) automates the deployment of code changes directly to production, with minimal human intervention. Continuous Delivery (CD) involves automating the delivery of code changes to a staging or pre-production environment for manual approval before going to production. Explain the role of Docker in containerization and how it benefits DevOps. – Docker is a containerization platform that packages applications and their dependencies into lightweight containers. DevOps benefits from Docker as it provides consistency, isolation, and portability, allowing for easy deployment and scaling of applications. What is Configuration Management, and how does Ansible help in this area? – Configuration Management is the practice of automating and managing the configuration of servers and infrastructure. Ansible is a configuration management tool that allows DevOps teams to define and apply infrastructure configurations as code, ensuring consistency and repeatability. What is Infrastructure as Code (IaC), and how does Terraform fit into DevOps? – IaC is the practice of managing and provisioning infrastructure using code. Terraform is an IaC tool that allows DevOps teams to define infrastructure in code and automatically create, update, and destroy resources. It enhances infrastructure agility and consistency. Explain the role of monitoring and alerting tools like Prometheus in