
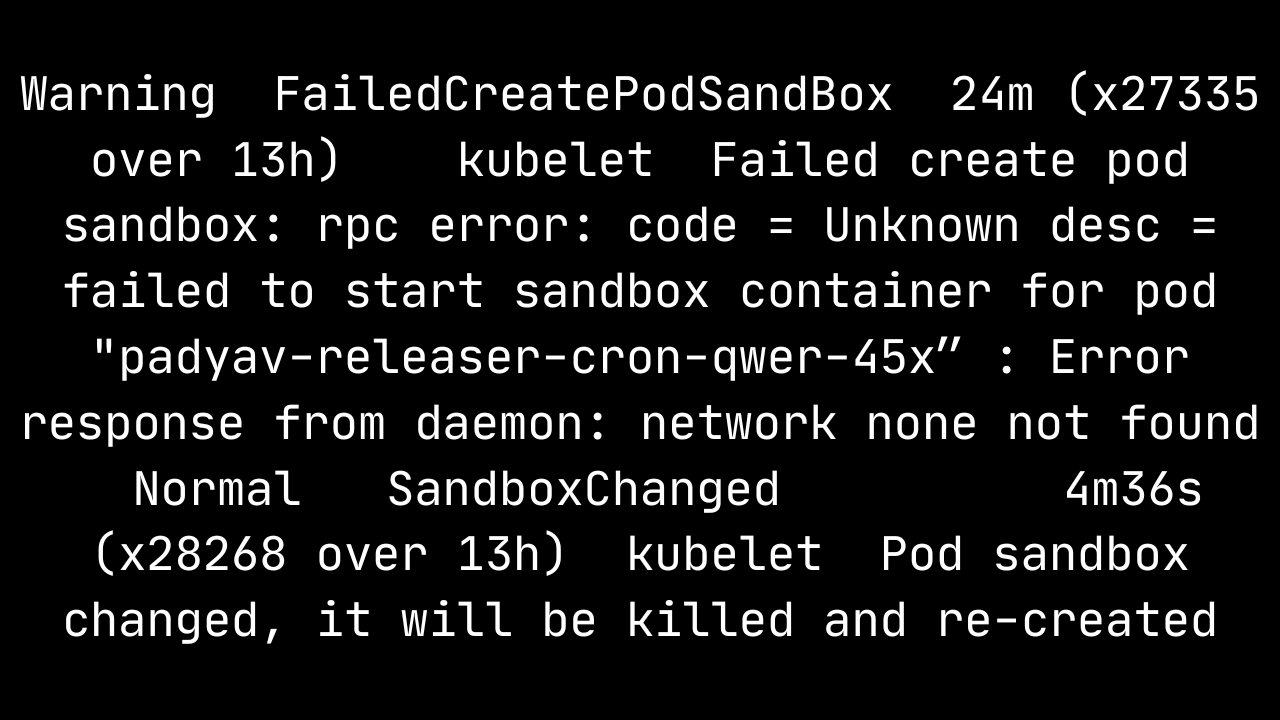
Troubleshooting :
– Checked the dedicated node having issues with docker
– When checked docker seems healthy enough to be passing checks but not healthy enough to run pods
– This scenario happens typically when underlying infra issue like I/O being exhausted but the node looked fine
– After few mins , the PODs in Error state came back normal and running
– Two days past : issue pops up again . The new node hits at 100% CPU utilisation instantly
– While digging further found out that Datadog agent has been installed/configured recently and no other changes
– Considering the DD memory usage , the Node instance type was bumped up to c5.xlarge to c5.2xlarge
– Even after change in node type change , the issue was intermittent .
– Upon digging further , found out the actual root cause
Actual root cause : Datadog integration with K8s – Earlier version of the library had issues with memory – the pod appear to be growing to 5gb and then failing at that point . Upon finding this , we got the full release version of the library and then things were stable with no memory issues. So the actual issue and fix was not about increasing the instance type with higher cpu/mem rather the unstable library